Claude Sonnet 5深度解析:Anthropic把Agent能力压进中量级模型,性能逼近Opus 4.8但价格不到一半——2026年Agent性价比新标杆
Anthropic于2026年6月30日发布Claude Sonnet 5——史上最强Agent中量级模型。性能逼近Opus 4.8,定价不到一半,首发$2/$10每百万token。五档Effort调节+100万上下文+免费版默认模型。深度解析SWE-bench Pro 63.2%背后的性价比革命。
2026年6月30日,Anthropic悄然丢出了一颗「深水炸弹」——Claude Sonnet 5正式发布。没有盛大的发布会,没有铺天盖地的预告,但这款被官方称为「有史以来最具Agent能力的Sonnet模型」的产品,几乎在一夜之间改写了AI Agent的性价比方程。
一句话概括Sonnet 5的定位:性能逼近Opus 4.8,价格不到一半,默认免费可用。对于每天要发起成千上万次模型调用的Agent应用开发者来说,这不是「又强了多少」的问题,而是「谁还烧得起旗舰模型」的问题。
本文将从基准测试、定价策略、Effort机制、安全性、竞品对比、选型建议六个维度,全面拆解Sonnet 5到底值不值得换。
一、核心参数速览
先上一组硬数据。Sonnet 5的规格单,如果用一句话翻译:把数月前需要旗舰模型才能跑的Agent任务,压到了中量级模型的价格区间。
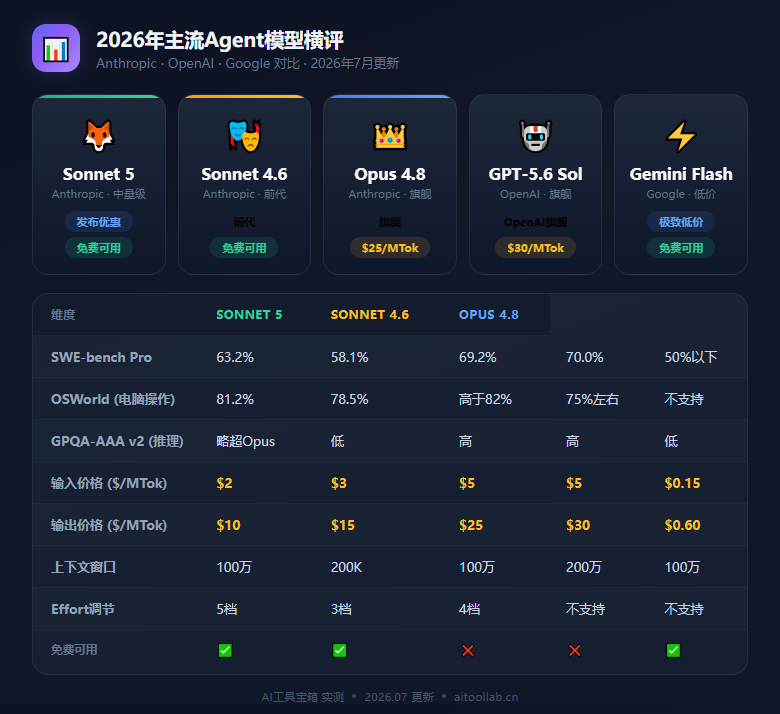
| 参数 | Claude Sonnet 5 | 对比参考 |
|---|---|---|
| API标识 | claude-sonnet-5 | — |
| 内部代号 | Fennec | 与Opus系列共享命名传统 |
| 上下文窗口 | 100万tokens | 与Opus 4.8持平 |
| 输入类型 | 文本 / 图像 / 文件 | 与Opus 4.8一致 |
| Effort等级 | low / medium / high / max / x-high | 比Opus 4.8多一个x-high档 |
| 发布价输入 | $2 / 百万token(至8月31日) | Opus 4.8为$5 |
| 发布价输出 | $10 / 百万token(至8月31日) | Opus 4.8为$25 |
| 标准价输入 | $3 / 百万token(9月1日起) | — |
| 标准价输出 | $15 / 百万token(9月1日起) | — |
| 可用平台 | API / Claude Code / 免费版默认 / Pro默认 / Bedrock / Foundry / Vertex | 覆盖最广的Sonnet模型 |
二、性能基准:逼近旗舰,部分反超
先说结论:Sonnet 5离Opus 4.8还有差距,但这个差距已经缩小到「值不值得多花一倍的钱」的级别。
以下是与Sonnet 4.6和Opus 4.8的核心基准对比:
| 基准测试 | Sonnet 5 | Sonnet 4.6 | Opus 4.8 | 解读 |
|---|---|---|---|---|
| SWE-bench Pro | 63.2% | 58.1% | 69.2% | Agentic Coding提升5.1个百分点,追到Opus的91% |
| SWE-bench Verified | 强(具体值未公开) | 79.6% | 88.6% | 普通编程任务差距更小 |
| OSWorld | 81.2% | 78.5% | 高于Sonnet 5 | 浏览器/桌面操作能力大幅跃升 |
| GPQA-AAA v2 | 略超Opus 4.8 | 低 | 高 | 研究生级推理——中量级首次反超旗舰 |
| BrowseComp | 接近Opus 4.8 | — | 领先 | Agent搜索场景,x-high可匹配旗舰 |
几个值得注意的细节:
- SWE-bench Pro提升至63.2%:相比Sonnet 4.6的58.1%提升了5.1个百分点。63.2%意味着在真实编程任务中,Sonnet 5能独立完成近三分之二的多文件修改,已经达到「能当半个初级工程师用」的水平。
- GPQA-AAA v2首次反超Opus 4.8:这是Sonnet系列首次在研究生级推理测试中超越旗舰。虽然优势微弱,但说明Anthropic在中量级模型里塞进了一些旗舰级的推理能力。
- OSWorld 81.2%:在桌面操作、浏览器自动化的计算机使用基准上,Sonnet 5相比前代大幅跃升。这是Agent场景最直接的性能指标。
当然,Opus 4.8仍然是不可替代的旗舰。在最难的编码任务、最苛刻的Agent场景、以及需要最高推理强度的工作负载上,Opus 4.8的领先优势依然稳固。Sonnet 5的价值在于——它让「够用」的价格降低了一半以上。
三、定价策略:限时优惠背后的抢位战
Sonnet 5的定价是整个发布最值得玩味的部分。它采用了两层定价结构:
发布优惠期(至2026年8月31日):输入 $2/百万token,输出 $10/百万token。
标准定价(9月1日起):输入 $3/百万token,输出 $15/百万token。
对比当前主流Agent模型的定价:
| 模型 | 输入 ($/MTok) | 输出 ($/MTok) | 定位 |
|---|---|---|---|
| Claude Sonnet 5(发布期) | $2 | $10 | 中量级Agent标杆 |
| Claude Sonnet 5(标准) | $3 | $15 | 中量级Agent标杆 |
| Claude Opus 4.8 | $5 | $25 | 旗舰级最高质量 |
| GPT-5.6 Sol | $5 | $30 | OpenAI旗舰 |
| Gemini 3.1 Pro | $2.5 | $10 | Google中高端 |
| Gemini 3.5 Flash | $0.15 | $0.60 | 极致低价 |
从定价表可以看出,Sonnet 5的发布期价格在输出端比Opus 4.8便宜60%,比GPT-5.6 Sol便宜67%。即使在标准定价阶段,它的价格也显著低于旗舰竞品。
有一个大多数媒体忽略的细节:Sonnet 5使用了更新的Tokenizer(与Opus 4.7引入的变更类似)。同样的文本可能在Sonnet 5中映射出1.0到1.35倍的token数。Anthropic设置发布期定价的初衷是「使迁移基本成本中性」——也就是说,每token单价降了,但实际消耗的token可能多了,两者大致抵消。对于从Opus 4.8降级的用户来说,实际节省仍然非常可观(节省40%-50%)。
TechCrunch的分析一针见血:现在Agent能力已是「入场标配」,真正的竞争差异正在从「能不能做Agent」转向「谁能更便宜、更可靠地做Agent」。Sonnet 5用两个月的限时优惠,正是在这条新战线上抢占默认选择的位置。
四、Effort Levels:一模型五档,成本精调的革命
Sonnet 5引入了五档可调推理强度(Effort Levels):low、medium、high、max、x-high(extra high)。这是本次发布中最被低估的功能。
- 低effort(low/medium):适合简单任务,如格式转换、摘要生成、基础问答。token消耗少,速度快,成本低。
- 中高effort(high/max):适合中等复杂度任务,如代码审查、多步推理、文档分析。
- 超高effort(x-high):将Sonnet 5推到性能极限,在OSWorld和BrowseComp等Agent基准上接近Opus 4.8的表现。
关键在于:同一个模型,用低effort跑长尾简单任务省钱,用高effort兜底复杂任务保持质量。这让团队可以用一套模型覆盖从廉价批处理到接近旗舰质量的整条曲线。
但也需要注意:在x-high模式下,Sonnet 5消耗的token量可能超过同任务下用Opus 4.8中等effort的成本。Anthropic把成本控制权交到了开发者手里,而不是像以前那样让用户在便宜和好用之间二选一。能否用好这个机制,考验的是团队的调度能力。
五、安全性:Agent更安全了,但不是旗舰级
在安全性方面,Sonnet 5相比Sonnet 4.6有可测量的改进:
- 不良行为率下降:在「配合滥用」「欺骗」等测试中发生率更低
- 幻觉率和谄媚率下降:更少编造信息,更少迎合用户
- Prompt Injection防御增强:更擅长抵御提示注入攻击的劫持尝试
- 网络安全防护默认启用:未针对网络攻击任务做专门训练,在Firefox 147漏洞利用测试中未能生成完整的工作型利用代码
Anthropic特别强调,Sonnet 5的网络攻击风险远低于Mythos级模型(如Claude Fable 5),因此「被政府强制下架的概率很低」。这是一个微妙的声明——它间接承认了Fable 5/Mythos 5之所以被出口管制,正是因为它们的安全防护不够成熟。Sonnet 5在定位上刻意与Mythos级拉开距离,既是为了安全,也是为了规避监管风险。
需要客观指出的是:Sonnet 5的安全水位仍低于Opus 4.8。对于金融、医疗等高风险场景,旗舰模型或额外的安全防护层仍然是更稳妥的选择。
六、竞品格局:Agent性价比大战全面开打
Sonnet 5的发布,让2026年下半年的AI Agent市场格局变得更加清晰:
6.1 直接对手:GPT-5.6 Sol
OpenAI的GPT-5.6 Sol系列以SWE-bench Pro 70%领先,但定价高达$5/$30,输出价格是Sonnet 5的三倍。如果你的Agent流水线以批量编码任务为主,Sonnet 5用40%的价格拿到了GPT-5.6 Sol 90%的编程能力,性价比优势明显。
6.2 降维对比:Gemini 3.5 Flash
Google的Gemini 3.5 Flash定价仅为$0.15/$0.60,是极致低价的代表。但它不是真正意义上的Agent模型——缺乏复杂的工具调用和自主规划能力。Sonnet 5在能自主执行这个维度上,与Flash完全不在一条赛道。
6.3 自身产品线:Anthropic的三档分层
Anthropic的产品线布局越来越清晰:
- Sonnet 5:高频、成本敏感的Agent流水线
- Opus 4.8:关键路径上的最高质量保障
- Fable 5(受限):极端场景下的超强能力(目前仅对政府合作方开放)
这个三档分层的策略,让Anthropic同时覆盖了从廉价Agent批量运行到旗舰级关键任务的全场景。
七、谁该换Sonnet 5?——选型决策指南
✅ 应该换Sonnet 5的情况:
- 你的Agent流水线每天调用数千次以上,对单次调用成本敏感
- 主要任务是自动化编码、浏览器操作、批量知识工作
- 正在用Sonnet 4.6——升级摩擦几乎为零(API标识切换即可)
- 需要在成本和能力之间灵活调节(effort机制是重要加分项)
❌ 应该继续用Opus 4.8的情况:
- 任务复杂度极高,单次调用质量比成本更重要
- 安全要求苛刻(金融合规、医疗诊断等)
- 每次调用是高价值独立任务而非海量批处理
- 不需要effort调节——就想在最高质量档位跑
🔶 建议观望的情况:
- 已经在用Gemini 3.5 Flash走便宜够用路线且效果满意的
- 关键业务依赖硬基准分数——等第三方评测机构(如LMSYS、SEAL)出独立报告后再决定
八、对开发者的实操影响
8.1 Claude Code集成
Sonnet 5发布当天即成为Claude Code的可用模型。如果你在Claude Code中切换到Sonnet 5,日常编码任务的体验与Opus 4.8的差距并不大——代码审查、Bug修复、重构建议等场景下,两者的输出质量非常接近。但在需要复杂多文件修改的大任务上,Opus 4.8的稳定性仍然更强。
8.2 第三方工具支持
Sonnet 5已确认获得以下工具和平台的支持:
- Cursor:官方合作伙伴,报告称Agent在「保持计划并干净地交付多步修改」方面表现优异
- Aider:已支持Sonnet 5作为后端模型
- GitHub Copilot:已集成Sonnet 5
- OpenRouter:多供应商路由已加入Sonnet 5选项
- AWS Bedrock / Google Vertex / Microsoft Foundry:三大云平台全部支持
8.3 早期用户反馈
Anthropic的早期合作伙伴描述了一个值得注意的模式:Sonnet 5会先写一个能重现Bug的测试,修复Bug,然后故意撤销修复来验证Bug确实回归——全部在一个pass中完成。这种主动验证自己工作的行为,以前只在Opus 4.8和Fable 5上出现过。Cursor报告称Sonnet 5的Agent更少偏离计划,Lovable则强调它对不安全请求的干净拒绝显著优于前代,ClickHouse的反馈集中在更紧密的推理步骤和更快的洞察速度。
九、一个隐藏信号:Agent能力正在「降级」为中量级标配
如果我们把Anthropic最近三个月的发布连起来看,会发现一条清晰的趋势线:
- 5月28日:Claude Opus 4.8发布——动态工作流,11天迁移75万行代码
- 6月9日:Claude Fable 5(Mythos级)发布——SWE-Pro 80.3%,随即被出口管制限制
- 6月30日:Claude Sonnet 5发布——Agent能力「降级」到中量级模型,价格砍半
这条线清晰地展示了一个行业规律:Agent能力正在从「旗舰独占」变成「标配功能」。就像当年智能手机的高端功能(大屏、多摄、快充)逐级下放到千元机一样,AI的Agent能力也在经历同样的「技术民主化」过程。
对开发者来说,几个时间节点值得关注:
- 短期:Sonnet 5是Agent项目的性价比最优解
- 中期:预计2026年底前,Sonnet级别的模型将全面覆盖Agent场景
- 长期:当Sonnet 6或7能以更低的价格提供Opus级别的Agent能力时,旗舰模型的定位将向更极端的场景(科研、国防、超大规模推理)转移
十、总结
Claude Sonnet 5不是一次令人惊叹的技术飞跃,而是一次精准的性价比革命。它没有在绝对性能上超越Opus 4.8,但它用不到一半的价格,提供了90%以上的Agent能力。
如果你是一个每天要运行成百上千次Agent调用的开发者,Sonnet 5就是目前市场上最理性的选择——默认模型已经是它了,切换成本几乎为零,性能足够好,价格足够低。
更何况,它还免费。在发布后的头几周,你完全可以在Claude Code或免费版Claude中零成本测试它的真实表现,然后决定是否在生产环境中大规模切换。
从更大的视角看,Sonnet 5的发布标志着AI行业进入了一个新阶段:「比谁更强」的军备竞赛正在向「比谁更便宜地强」的性价比战争过渡。对于每天烧token烧到肉疼的开发者来说,这无疑是好消息。
参考来源:Anthropic官方公告、TechCrunch、AIMadeTools基准数据库、Cursor/Lovable/ClickHouse合作伙伴反馈。数据截至2026年7月2日。