OpenAI首款自研芯片Jalapeño深度解析:联手博通9个月流片、专攻推理降本50%——AI算力从「英伟达依赖」走向「全栈自研」的转折时刻
2026年6月25日,OpenAI发布首款自研AI推理芯片Jalapeño,与博通联手仅9个月完成从设计到流片,刷新行业纪录。芯片专攻推理场景,预计2026年底部署,性能对标英伟达Blackwell。本文从技术规格、合作模式、全栈战略、行业背景(微软Maia 200/谷歌TPU/亚马逊Trainium)到对AI开发者的影响,全面深度解析这一AI算力格局的转折性事件。
2026年6月25日,OpenAI投下了一枚震撼弹——正式发布其首款自研AI推理芯片Jalapeño(哈拉贝诺辣椒)。这枚由OpenAI与半导体巨头博通(Broadcom)联合开发的ASIC芯片,从设计到流片仅用了9个月,OpenAI自称是"高性能先进半导体领域有史以来最快的ASIC开发周期"。
更关键的是,Jalapeño并非追求全能——它是一款专注推理(inference)的专用芯片,不涉及训练(training)。这一看似"保守"的定位,实则精准命中了AI商业化的核心痛点:推理成本。
为什么推理比训练更值得自研?训练是一次性的资本投入,而推理是每天数亿用户持续产生的运营成本。在OpenAI的体量下——每天处理数十亿次API调用、ChatGPT周活用户超5亿——推理成本的任何百分比下降,都将转化为巨额的利润空间。
本文将从技术规格、合作模式、全栈战略、行业竞争格局到开发者影响,深度拆解这个AI算力格局的历史转折点。
一、Jalapeño芯片的技术密码
1.1 ASIC路线:不追求全能,只做推理王者
Jalapeño是一款ASIC(专用集成电路),这意味着它从硅片层面就被优化为只做一件事——高效执行大语言模型的推理计算。与通用GPU(如图形渲染+科学计算+AI训练全部兼顾的英伟达H100/B200)不同,ASIC芯片可以砍掉所有推理不需要的电路模块,在同样面积的硅片上塞入更多的矩阵乘法单元。
OpenAI总裁Greg Brockman在内部播客中解释了这一逻辑:"我们对自己的工作负载有深刻理解,一直在寻找那些需求尚未被充分满足的特定场景,思考如何针对性地构建加速能力。"
博通CEO陈福阳(Hock Tan)在路透社采访中更直接表态:Jalapeño的性能可与英伟达Blackwell系列及谷歌TPU相媲美。
1.2 九个月流片:AI辅助造芯的"飞轮"
传统高性能芯片从设计到流片通常需要2到3年。Jalapeño仅用9个月完成全流程,这背后是一个令人兴奋的"自增强循环":
- ChatGPT辅助芯片设计:OpenAI的AI模型在芯片设计过程中被用于加速工程迭代与验证——布图规划、时序分析、功耗优化等环节都有AI参与
- 博通的制造经验:博通在ASIC定制芯片领域深耕数十年,拥有成熟的物理设计、封装和测试能力
- 推理芯片相对简单:与训练芯片相比,推理芯片的逻辑设计更简洁,不需要处理复杂的分布式训练通信
OpenAI在公告中提出了一个具有深远意义的观点:"如果AI能帮助工程师更快地设计出更好的芯片,就可以降低整个行业的计算成本,帮助普及先进AI的使用权限。"这是一个AI造芯片→芯片跑AI→AI更好地造芯片的闭环逻辑。
1.3 已知技术指标(基于公开信息)
虽然Jalapeño仍在测试阶段,OpenAI尚未公布完整规格,但从官方公告和媒体采访中我们已能拼凑出关键轮廓:
| 维度 | Jalapeño(OpenAI) | 说明 |
|---|---|---|
| 芯片类型 | ASIC(专用集成电路) | 仅服务于AI推理 |
| 制程工艺 | 未公布(推测TSMC 3nm) | 博通合作伙伴为台积电 |
| 开发周期 | 9个月(设计→流片) | 传统芯片需2-3年 |
| 合作方 | 博通(Broadcom) | 2025年10月官宣合作 |
| 性能对标 | 英伟达Blackwell / 谷歌TPU | 博通CEO公开表述 |
| 能效优势 | "显著优于当前最先进同类产品" | OpenAI官方声明 |
| 部署时间 | 2026年底前 | 目前处于测试阶段 |
| 主要用途 | ChatGPT、Codex、API、智能体产品 | OpenAI全系产品推理 |
| 定价策略 | 未公布 | 目标:大幅降低推理成本 |
二、为什么是博通?合作背后的战略逻辑
OpenAI选择博通而非自建芯片团队从头开始,背后有清晰的商业逻辑:
2.1 博通的ASIC帝国
博通是全球最大的ASIC定制芯片服务商,其客户包括谷歌(TPU)、Meta(MTIA)等科技巨头。博通的商业模式是"你提需求,我造芯片"——客户定义芯片架构和规格,博通负责物理设计、验证、流片和量产。这种模式让OpenAI可以绕过从零组建数百人芯片团队的时间和成本。
2.2 九个月的神速从何而来
博通在ASIC领域的积累是其速度的关键:
- 成熟的IP库:博通拥有大量已验证的芯片IP模块(内存控制器、PCIE接口、SerDes等),OpenAI只需设计核心计算单元
- 台积电的先进制程:博通与台积电深度绑定,可优先获得3nm产能
- AI辅助设计:ChatGPT参与芯片设计加速了验证和迭代效率
- 推理芯片架构简单:相比训练芯片,无需处理复杂的多卡互联拓扑和分布式通信
2.3 与Cerebras的前缘
值得关注的是,OpenAI此前曾与AI芯片公司Cerebras有过接触。Cerebras以其巨型晶圆级芯片WSE-3闻名,主打训练场景。OpenAI最终选择博通+推理路线,说明其在"训练vs推理"的战略选择上,果断偏向了推理——训练可以用英伟达,推理必须自己做。
三、OpenAI的全栈野心:从芯片到应用的垂直整合
Jalapeño的发布不只是"多了一款芯片",而是OpenAI全栈战略的关键落子。OpenAI在公告中的这段话值得全文引用:
"OpenAI不仅在开发前沿模型,也在构建其上的产品;更重要的是,我们正在设计它们之下的基础设施——包括芯片架构、内核、内存系统、网络、调度、部署系统乃至产品体验。因为OpenAI贯穿整个技术栈,每一层都可以围绕同一个目标进行优化:让我们的模型对用户而言更快、更稳定、更实惠。"
这是一个苹果式的垂直整合逻辑。回顾苹果从依赖三星/高通到自己设计A系列芯片的历程,你会发现惊人的相似——当一家公司同时控制芯片、操作系统和应用层,每一层都可以为最终用户体验做极致优化。
OpenAI的全栈路径:
- 芯片层:Jalapeño → 未来更多代芯片("多代计算平台的第一步")
- 系统层:内核、内存系统、网络、调度器 → 自研数据中心基础设施
- 模型层:GPT系列、Codex → 持续迭代前沿模型
- 产品层:ChatGPT、API、智能体 → 触达数十亿用户
这个闭环一旦完整运行,OpenAI将拥有竞争对手难以复制的系统性成本优势——英伟达GPU的溢价+云厂商的利润加成都将被压缩到自研芯片+自建基础设施的成本结构中。
四、行业全景:科技巨头的集体"去英伟达化"
Jalapeño并非孤例。2026年,一场围绕AI芯片的"去英伟达化"运动正在全面展开。四大云厂商均已亮出自研芯片的底牌:
4.1 微软Maia 200:性能碾压式登场
2026年1月,微软发布第二代自研AI加速器Maia 200。基于台积电3nm工艺,1400亿+晶体管,216GB HBM3e内存,FP8性能约5000 TFLOPS,FP4性能约10200 TFLOPS。微软官方宣称其FP4性能是亚马逊Trainium3的4倍、FP8性能超谷歌TPU v7达9%。每美元性能比第一代Maia 100提升30%。
4.2 谷歌TPU:最早的自研旗帜
谷歌是自研AI芯片的先行者,TPU系列已迭代至第七代(Trillium)。2026年推出TPU 8i——一款专为推理优化的芯片,SRAM容量增加3倍,可缓存模型权重减少HBM访问,针对Gemini模型做深度协同优化。在GCP上,TPU定价通常比GPU低20-30%。
4.3 亚马逊Trainium:对外销售的差异化策略
亚马逊的策略与微软、谷歌不同——它不仅将Trainium3用于AWS自有服务,还在对外销售这些芯片。Trn3 UltraServer(144颗芯片组成的机架,362 petaflops FP8)已向云客户开放。这一策略意味着"去英伟达化"不仅是云厂商的内部事务,中小公司也能享受自研芯片的红利。
4.4 Meta MTIA:社交推理专用
Meta的自研芯片MTIA(Meta Training and Inference Accelerator)主攻推荐系统和社交内容的推理场景——新闻Feed排序、广告推荐、内容审核等。虽然不对外销售,但其大规模内部部署已经显著降低了Meta的推理成本。
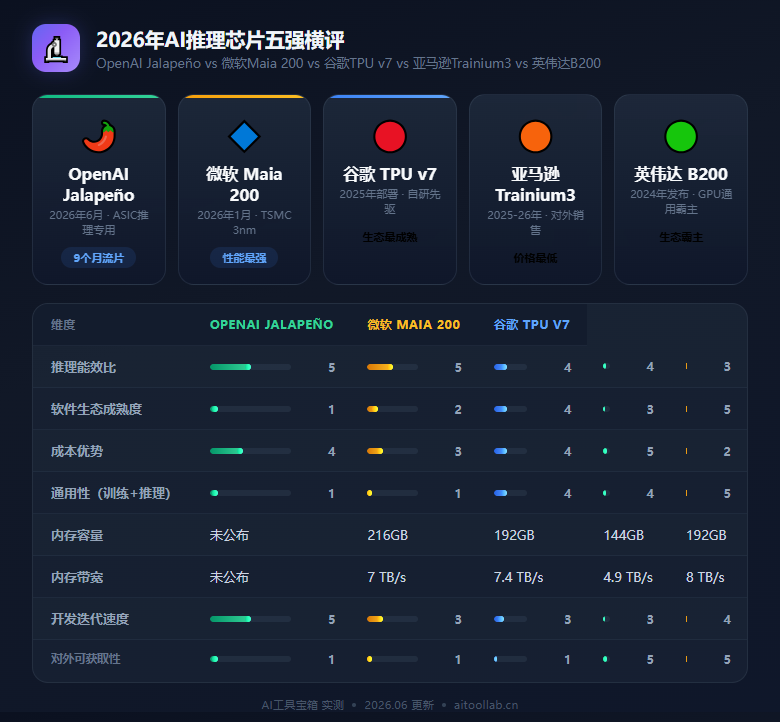
4.5 五强对比:自研AI推理芯片一览
| 维度 | OpenAI Jalapeño | 微软Maia 200 | 谷歌TPU v7 | 亚马逊Trainium3 | 英伟达B200 |
|---|---|---|---|---|---|
| 发布时间 | 2026年6月 | 2026年1月 | 2025年 | 2025-2026年 | 2024年 |
| 芯片类型 | ASIC(推理) | ASIC(推理) | ASIC(推理+训练) | ASIC(训练+推理) | GPU(通用) |
| 制程 | 推测3nm | TSMC 3nm | TSMC 5nm | TSMC 3nm | TSMC 4nm |
| 内存 | 未公布 | 216GB HBM3e | 192GB | 144GB | 192GB HBM3e |
| 内存带宽 | 未公布 | 7 TB/s | 7.4 TB/s | 4.9 TB/s | 8 TB/s |
| 开发周期 | 9个月 | ~2年 | ~2年 | ~2年 | ~3年 |
| 对外销售 | 否 | 否(Azure) | 否(GCP) | 是 | 是 |
| 生态成熟度 | 待建设 | 早期 | 较成熟 | 中期 | 最成熟(CUDA) |
| 核心优势 | 开发极快、AI辅助设计 | 性能最强、内存最大 | 生态最成熟 | 价格最低、对外销售 | 通用性最强、生态霸主 |
五、为什么推理成本是"房间里的大象"
很多人低估了推理成本在AI商业化中的权重。让我们算一笔账:
5.1 训练vs推理:成本的天平
训练一个大模型(如GPT-5)可能花费数亿美元,但这笔钱花一次就够了。推理则是每天都在烧钱——ChatGPT每次回答一个问题、API每次返回一段代码,都在消耗算力。
以ChatGPT的体量估算:假设日均100亿次请求,每次请求平均生成500个token,每百万token的推理成本约$2(使用英伟达A100/H100),那么每天的推理成本高达$100万,一年超过$3.65亿。这还只是保守估计。
如果Jalapeño能将推理成本降低30-50%,对于OpenAI来说就是每年节省$1-2亿的纯利润。
5.2 推理成本的下降曲线
从2022年到2026年,大模型推理成本已经下降了约1000倍(GPT-3时代每百万token约$60,如今GPT-5.5 Instant已降至约$0.15)。但这一下降主要来自模型优化(蒸馏、量化、MoE架构等),硬件端的降本才刚刚开始。
Jalapeño代表的ASIC路线,可能开启推理成本新一轮的指数级下降——因为ASIC芯片可以针对特定模型架构做极致的物理优化,这是通用GPU永远无法做到的。
六、对AI行业的影响:五个关键变化
6.1 推理成本战将成为2027年主旋律
随着各大云厂商自研芯片纷纷在2026-2027年量产部署,推理成本将进入真正的竞争定价时代。过去AI公司靠英伟达GPU的算力溢价赚钱,未来将变成算力成本就是运营成本的"薄利时代"。这对AI应用开发者是重大利好——更多AI产品将变得经济可行。
6.2 英伟达的护城河正在被"分片"蚕食
英伟达最大的护城河不是硬件性能,而是CUDA生态。但ASIC芯片的进攻采取的是"分片"策略:不在所有场景挑战英伟达,只在推理这个最大、最值钱的场景抢份额。训练场景英伟达暂时不可替代(CUDA生态、分布式训练框架),但推理场景的替代窗口已经打开。
6.3 模型设计的"硬件适配"时代到来
过去,AI研究员设计模型时默认假设"跑在英伟达GPU上"。未来,模型可能需要针对不同芯片架构做适配——针对Maia 200的FP4精度优化、针对TPU 8i的SRAM缓存优化、针对Jalapeño的特定算子优化。模型架构和芯片架构的协同设计将成为核心竞争力。
6.4 AI辅助造芯的飞轮效应
Jalapeño的9个月开发周期已证明AI可以加速芯片设计。随着AI能力持续提升,"AI造芯片→芯片跑AI→更好的AI造更好的芯片"的正反馈循环将越来越快。这可能导致芯片设计的摩尔定律2.0——不是靠晶体管密度翻倍,而是靠AI加速设计-验证-迭代的每个环节。
6.5 中国AI芯片赛道的机会窗口
在全球"去英伟达化"浪潮中,中国AI芯片厂商(华为昇腾、寒武纪、壁仞科技、摩尔线程等)面临独特的机会。由于出口管制,中国企业本就无法自由采购最先进的英伟达芯片,这反而加速了国产替代。华为昇腾910B在部分推理场景已接近A100水平,随着自研芯片浪潮的全球共振,国产AI芯片的窗口期正在打开。
七、风险与挑战:Jalapeño不是万能药
尽管前景诱人,Jalapeño仍面临多重挑战:
- 软件生态从零建设:CUDA生态积累了15年,拥有数百万开发者、数千个优化库。OpenAI需要建设自己的编译器、驱动、推理框架——这不是一两年能完成的
- 尚未公布完整规格:目前只有"性能对标Blackwell/TPU"的定性表述,缺乏具体的浮点性能、内存带宽、功耗等数据。真实表现还需等待独立评测
- 只做推理、不做训练:这意味着训练场景仍需依赖英伟达,Jalapeño不是"完全替代"方案
- 单一客户风险:与博通合作的ASIC芯片本质上是"给OpenAI定制"的,无法像英伟达GPU那样对外销售分摊研发成本
- 摩尔定律的追赶:英伟达每年迭代一代GPU(H100→H200→B200→GB200),Jalapeño能否保持迭代速度跟上?
八、FAQ
Q1: Jalapeño会降低ChatGPT的价格吗?
会的,但不会立竿见影。OpenAI的目标是通过自研芯片将推理成本降低30-50%,部分节省将转化为用户降价。但Jalapeño预计2026年底才部署,实际价格调整可能在2027年。
Q2: Jalapeño和英伟达B200比谁更强?
这取决于具体场景。在通用计算上(如训练、图形渲染),B200毫无疑问更强。但在特定推理场景(如运行GPT系列模型),Jalapeño作为定制ASIC可能实现更高的能效比。博通CEO称Jalapeño"可与Blackwell及TPU相媲美"。
Q3: 这会影响我选择AI服务吗?
短期不会。长期来看,自研芯片带来的成本优势可能使OpenAI在定价上更有竞争力。如果你是大批量API用户,2027年后可能看到降价。对普通用户来说,ChatGPT不太可能涨价。
Q4: 中国公司能做出类似的芯片吗?
技术上可以,但面临制造端的制约(先进制程受限)。华为昇腾、寒武纪等已经在推理芯片领域有所布局,但距离3nm制程尚有差距。不过,对于国产大模型(如DeepSeek V4、豆包、通义千问),国产推理芯片的适配可能是比追赶3nm更现实的路径。
九、写在最后
Jalapeño的发布不只是一款芯片的诞生,它是AI行业从"依赖英伟达"走向"全栈自研"的宣言。当OpenAI、微软、谷歌、亚马逊、Meta全部亮出自研芯片,算力市场的垄断时代正在走向终结。
对于AI应用开发者来说,这是一个好消息——更多竞争意味着更低的推理成本、更多的硬件选择。对于英伟达来说,这既是挑战也是鞭策——垄断地位的松动可能倒逼其加快创新步伐。
而对于我们这些关注AI行业的人来说,Jalapeño的9个月开发周期暗示了一个更深刻的未来:AI不仅改变软件,也在改变硬件。当AI开始设计运行AI的芯片时,我们正在进入一个自我加速的技术纪元。
推荐工具
- OpenAI Codex — AI编程助手,基于GPT模型
- ChatGPT — 全球最流行的AI对话助手
- Claude — Anthropic旗舰AI助手
- Gemini — 谷歌多模态AI模型
- Cursor — AI原生代码编辑器
- GitHub Copilot — 微软AI编程助手